パレート図は品質管理の分野でよく使われる二軸のグラフです。左側の主軸(縦軸)に対して降順にならべた棒グラフを描き、右側の第二軸(副軸)に対して累積構成比を折れ線グラフで描きます。データの中から大きな割合を占める要因を可視化することができます。
Packages and Datasets
本ページではR version 3.4.4 (2018-03-15)の標準パッケージ以外に以下の追加パッケージを用いています。
| Package | Version | Description |
|---|---|---|
| tidyverse | 1.2.1 | Easily Install and Load the ‘Tidyverse’ |
また、本ページでは以下のデータセットを用いています。
| Dataset | Package | Version | Description |
|---|---|---|---|
| pareto_data | NA | NA | Original (private) |
事前準備
描画対象となるデータは以下のようなデータです。
pareto_data## # A tibble: 49 x 8
## id A B C D E F G
## <int> <int> <int> <int> <int> <int> <int> <int>
## 1 1 113 206 1754 776 203 72 1110
## 2 2 86 143 188 273 192 58 242
## 3 3 85 68 72 237 60 46 152
## 4 4 58 35 52 214 42 29 119
## 5 5 45 24 43 72 38 17 73
## 6 6 44 17 34 59 23 17 55
## 7 7 39 16 33 43 17 16 52
## 8 8 17 16 26 38 17 16 46
## 9 9 17 16 20 32 16 16 44
## 10 10 16 15 17 17 16 14 24
## # ... with 39 more rows
各グループの合計値をパレート図にしますので、まずは、tidy dataに変換し、グループ毎の合計値を求めておきます。
pareto_data %>%
tidyr::gather(key = "group", value = "value", -id) %>%
dplyr::select(group, value) %>%
tidyr::drop_na() %>%
dplyr::group_by(group) %>%
dplyr::summarise(value = sum(value))## # A tibble: 7 x 2
## group value
## <chr> <int>
## 1 A 715
## 2 B 837
## 3 C 2536
## 4 D 2041
## 5 E 818
## 6 F 568
## 7 G 2121
降順に描く
パレート図は値の大きな順にグラフを描きますので、先ほど求めた合計値をvalueをキーにして降順に並べ替えます。
pareto_data %>%
tidyr::gather(key = "group", value = "value", -id) %>%
dplyr::select(group, value) %>%
tidyr::drop_na() %>%
dplyr::group_by(group) %>%
dplyr::summarise(value = sum(value)) %>%
dplyr::arrange(dplyr::desc(value))## # A tibble: 7 x 2
## group value
## <chr> <int>
## 1 C 2536
## 2 G 2121
## 3 D 2041
## 4 B 837
## 5 E 818
## 6 A 715
## 7 F 568
これで、主軸側の棒グラフを描くのに必要なデータが揃いましたので、ggplo2パッケージを用いてグラフを描いてみます。
pareto_data %>%
tidyr::gather(key = "group", value = "value", -id) %>%
dplyr::select(group, value) %>%
tidyr::drop_na() %>%
dplyr::group_by(group) %>%
dplyr::summarise(value = sum(value)) %>%
dplyr::arrange(dplyr::desc(value)) %>%
ggplot2::ggplot(ggplot2::aes(x = group)) +
ggplot2::geom_bar(ggplot2::aes(y = value), stat = "identity")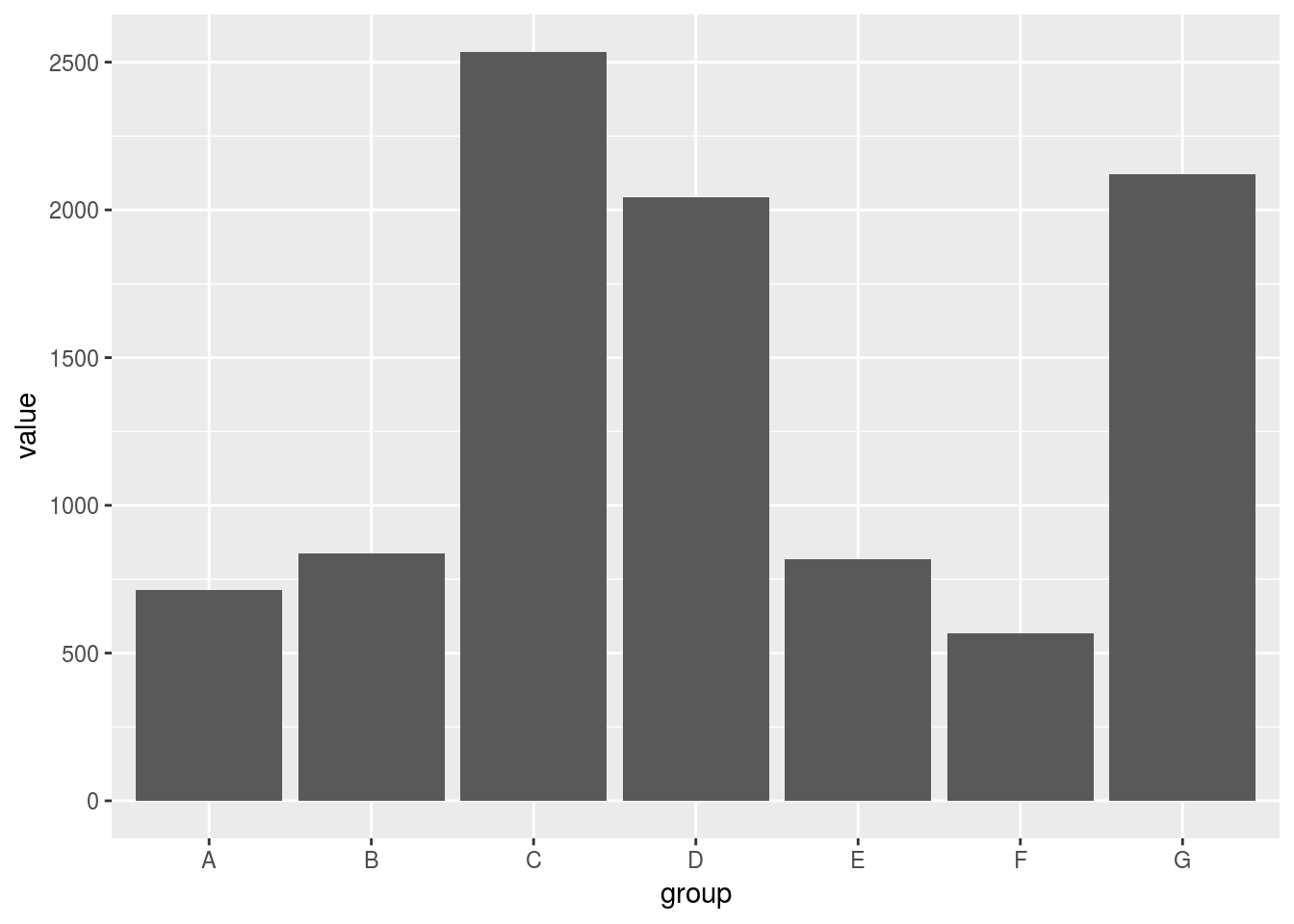
データを降順に並べたにも関わらずアルファベット順にソートされてしまいました。これを回避するためには横軸を因子型データに変換しておく必要があります。因子型データの操作にはtidyverseファミリーのforcatsパッケージを用います。
因子型データへの変換
データを降順に並べ変えた後にgroup変数を因子型データに変換します。因子型データの変換にはbase::as.factor関数ではなくforcats::as_factor関数を用います。base::as_factor関数は因子型変数に変換する際に水準をアルファニューメリック順に並べ替えてしまうので、今回のようにデータを降順にしたい場合は出現順に水準を割り当ててくれるforcats::as_factor関数の方が便利なためです。
group変数を因子型データに変換したもので棒グラフを描くと
pareto_data %>%
tidyr::gather(key = "group", value = "value", -id) %>%
dplyr::select(group, value) %>%
tidyr::drop_na() %>%
dplyr::group_by(group) %>%
dplyr::summarise(value = sum(value)) %>%
dplyr::arrange(dplyr::desc(value)) %>%
dplyr::mutate(group = forcats::as_factor(group)) %>%
ggplot2::ggplot(ggplot2::aes(x = group)) +
ggplot2::geom_bar(ggplot2::aes(y = value), stat = "identity")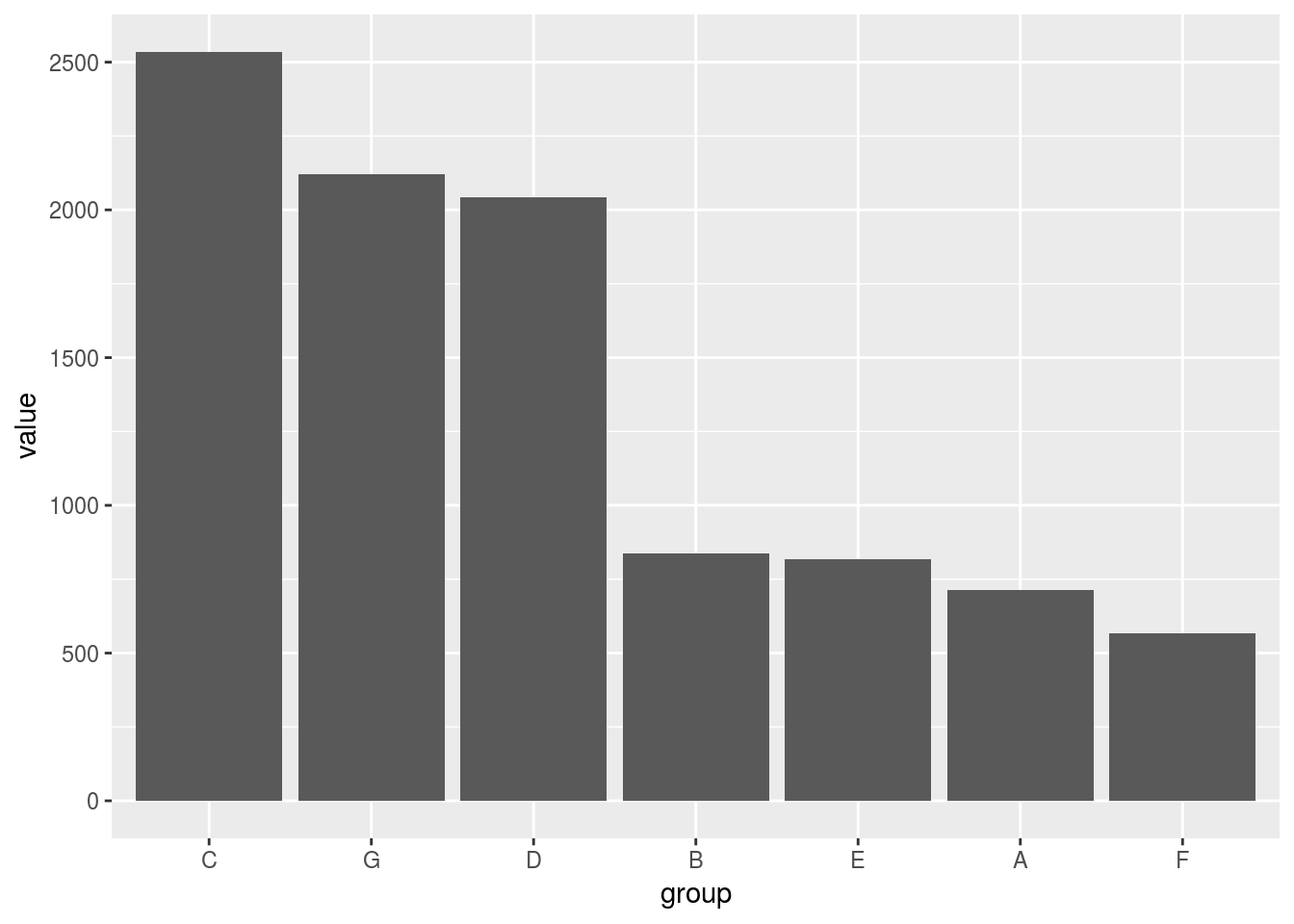
このようにvalueの値順(降順)に並んで描けます。
累積構成比を描く
次に累積構成比の折れ線グラフを描くために累積構成比を計算しておきます。
pareto_data %>%
tidyr::gather(key = "group", value = "value", -id) %>%
dplyr::select(group, value) %>%
tidyr::drop_na() %>%
dplyr::group_by(group) %>%
dplyr::summarise(value = sum(value)) %>%
dplyr::arrange(dplyr::desc(value)) %>%
dplyr::mutate(group = forcats::as_factor(group)) %>%
dplyr::mutate(cum = cumsum(value), cumrate = cum / sum(value))## # A tibble: 7 x 4
## group value cum cumrate
## <fct> <int> <int> <dbl>
## 1 C 2536 2536 0.263
## 2 G 2121 4657 0.483
## 3 D 2041 6698 0.695
## 4 B 837 7535 0.782
## 5 E 818 8353 0.867
## 6 A 715 9068 0.941
## 7 F 568 9636 1
棒グラフに重ねる前に累背構成比の折れ線グラフを確認しておきます。
pareto_data %>%
tidyr::gather(key = "group", value = "value", -id) %>%
dplyr::select(group, value) %>%
tidyr::drop_na() %>%
dplyr::group_by(group) %>%
dplyr::summarise(value = sum(value)) %>%
dplyr::arrange(dplyr::desc(value)) %>%
dplyr::mutate(group = forcats::as_factor(group)) %>%
dplyr::mutate(cum = cumsum(value), cumrate = cum / sum(value)) %>%
ggplot2::ggplot(ggplot2::aes(x = as.integer(group))) +
ggplot2::geom_line(ggplot2::aes(y = cumrate)) +
ggplot2::geom_point(ggplot2::aes(y = cumrate)) 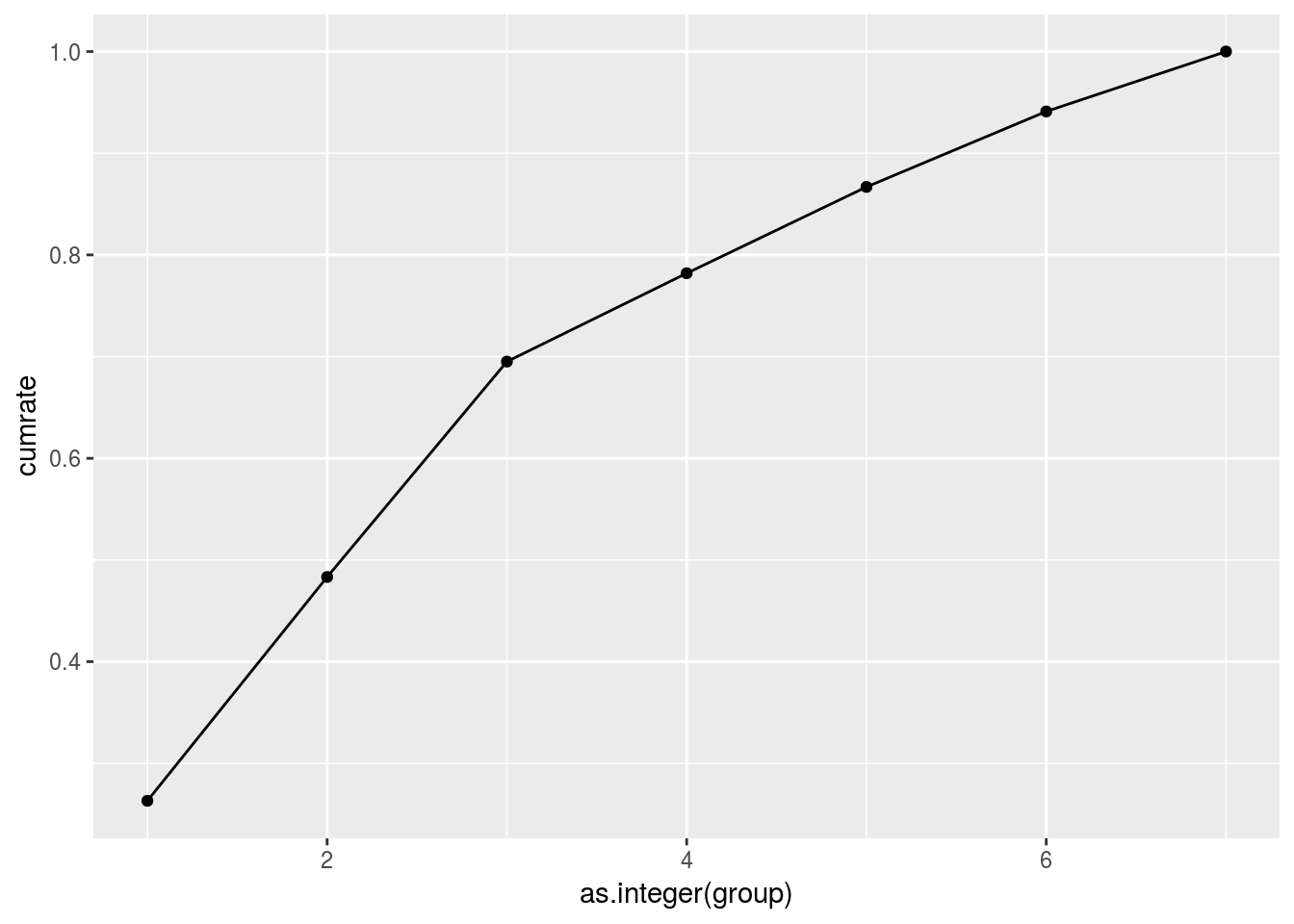
第二軸の準備
ggplot2パッケージにおける第二軸は軸を表示するのみであり、実際に描くグラフのデータは主軸(第一軸)のスケールに合わせる必要があります。今回の場合、value変数の最大値が2,500ちょとであることから、第二軸の最大値である1.0を2,500倍することでスケールを合わせます。
第二軸を表示するにはggplot2::scale_y_continious関数でsec.axis変数にスケール値を指定します。
pareto_data %>%
tidyr::gather(key = "group", value = "value", -id) %>%
dplyr::select(group, value) %>%
tidyr::drop_na() %>%
dplyr::group_by(group) %>%
dplyr::summarise(value = sum(value)) %>%
dplyr::arrange(dplyr::desc(value)) %>%
dplyr::mutate(group = forcats::as_factor(group)) %>%
dplyr::mutate(cum = cumsum(value), cumrate = cum / sum(value)) %>%
ggplot2::ggplot(ggplot2::aes(x = group, y = value)) +
ggplot2::scale_y_continuous(sec.axis = ggplot2::sec_axis(~ . / 2500,
name = "累積構成比"))
前述のようにスケール合わせをするために累積構成比であるcumrate変数を2,500倍しておきます。
pareto_data %>%
tidyr::gather(key = "group", value = "value", -id) %>%
dplyr::select(group, value) %>%
tidyr::drop_na() %>%
dplyr::group_by(group) %>%
dplyr::summarise(value = sum(value)) %>%
dplyr::arrange(dplyr::desc(value)) %>%
dplyr::mutate(group = forcats::as_factor(group)) %>%
dplyr::mutate(cum = cumsum(value), cumrate = cum / sum(value) * 2500)## # A tibble: 7 x 4
## group value cum cumrate
## <fct> <int> <int> <dbl>
## 1 C 2536 2536 658.
## 2 G 2121 4657 1208.
## 3 D 2041 6698 1738.
## 4 B 837 7535 1955.
## 5 E 818 8353 2167.
## 6 A 715 9068 2353.
## 7 F 568 9636 2500
実際に描く場合には横軸が因子型データになりますので、折れ線グラフの描画にはggplot2::geom_path関数を用います。
pareto_data %>%
tidyr::gather(key = "group", value = "value", -id) %>%
dplyr::select(group, value) %>%
tidyr::drop_na() %>%
dplyr::group_by(group) %>%
dplyr::summarise(value = sum(value)) %>%
dplyr::arrange(dplyr::desc(value)) %>%
dplyr::mutate(group = forcats::as_factor(group)) %>%
dplyr::mutate(cum = cumsum(value), cumrate = cum / sum(value) * 2500) %>%
ggplot2::ggplot(ggplot2::aes(x = group)) +
ggplot2::scale_y_continuous(sec.axis = ggplot2::sec_axis(~ . / 2500,
name = "累積構成比(折れ線)",
breaks = seq(0, 1, 0.2))) +
ggplot2::geom_bar(ggplot2::aes(y = value, fill = group), stat = "identity") +
ggplot2::geom_path(ggplot2::aes(y = cumrate, group = 0)) +
ggplot2::geom_point(ggplot2::aes(y = cumrate)) +
ggplot2::labs(x = "", y = "", title = "Pareto chart") +
ggplot2::scale_fill_brewer(palette = "Set3")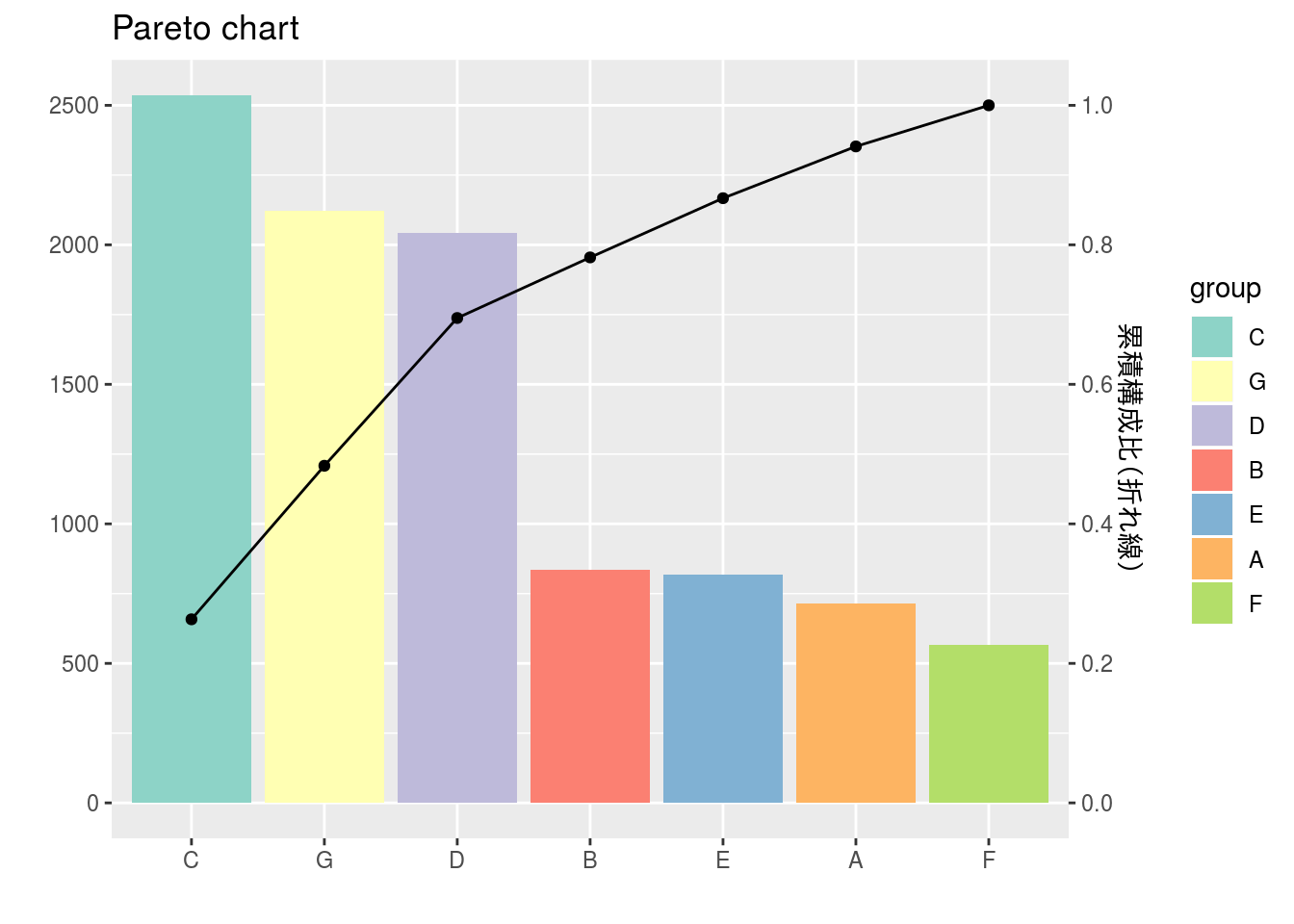
ENJOY!