データ分析を行うにあたりデータの分布を確認しておくことは重要なポイントのひとつです。データの分布を確認する基本的な方法としては、ヒストグラム、箱ひげ図、散布図などありますが、データ項目が多いとグラフを描くのも一苦労です。そこで、利用したいのが複数の散布図を一度に描く散布図行列(ペアプロット)です。ただし、ペアプロットを描く場合、描くグラフの数はデータ項目数の二乗個になり処理に時間がかかることに注意してください。
Packages and Datasets
本ページでは標準パッケージ以外に以下の追加パッケージを用いています。
| Package | Version | Description |
|---|---|---|
| tidyverse | 1.2.1 | Easily Install and Load the ‘Tidyverse’ |
| GGally | 1.4.0 | Extension to ‘ggplot2’ |
| psych | 1.8.10 | Procedures for Psychological, Psychometric, and Personality Research |
また、本ページでは以下のデータセットを用いています。
| Dataset | Package | Version | Description |
|---|---|---|---|
| iris | datasets | 3.4.4 | Edgar Anderson’s Iris Data |
| mtcars | datasets | 3.4.4 | Motor Trend Car Road Tests |
| airquality | datasets | 3.4.4 | New York Air Quality Measurements |
古典的な散布図行列
Base Plot
データフレームをplot関数に渡すと自動的に散布図行列を描いてくれます。
plot(iris)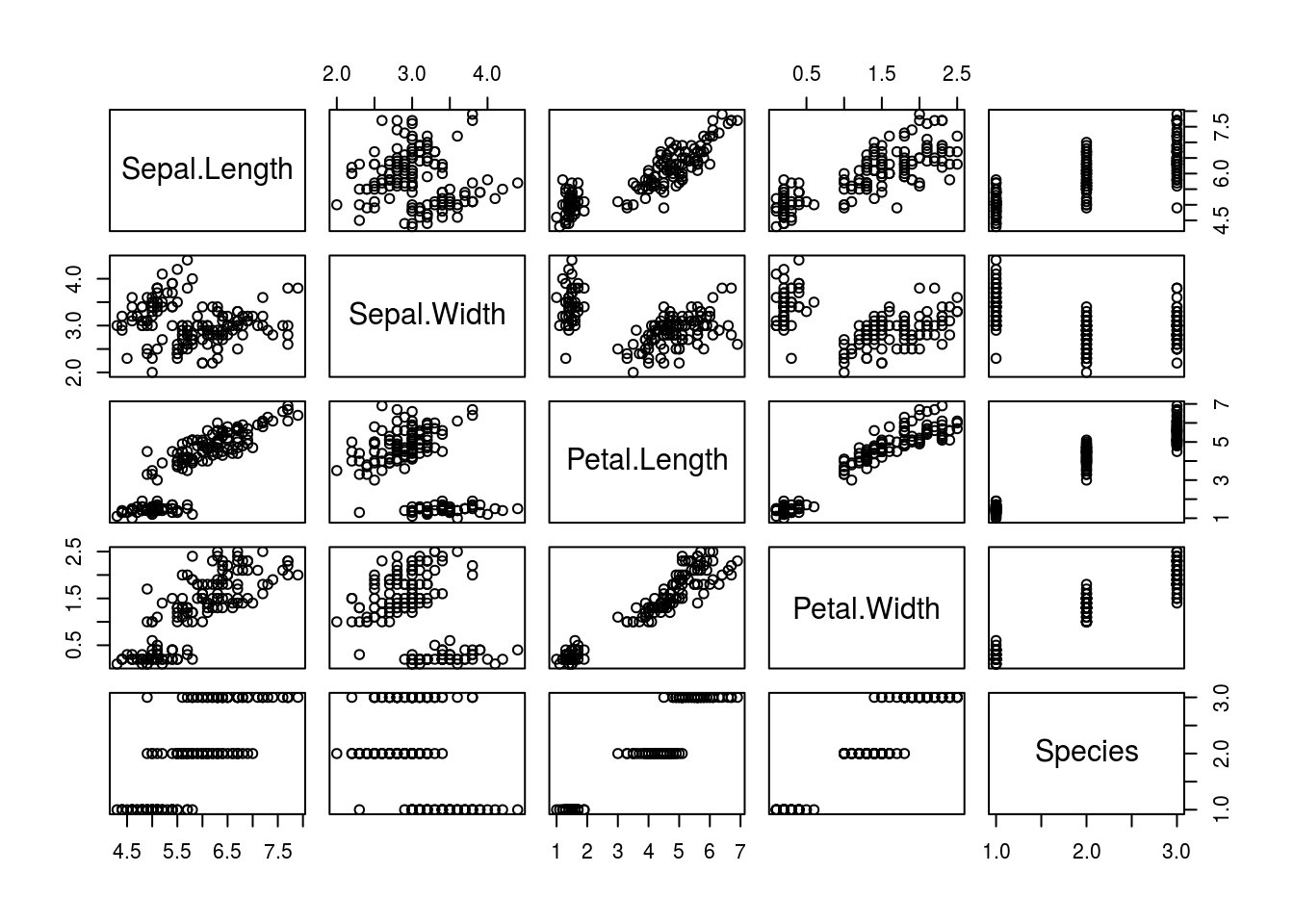
Package psych
psych::pairs.panels関数は散布図行列とともに相関係数を描画してくれます。更に対角にはデータ分布を描いてくれますのでplot関数よりは様々な情報を一度に把握することができます。なお、相関係数は以下から選択可能です。
| 指定方法 | 計算される相関係数 | 備考 |
|---|---|---|
| method = “pearson” | ピアソンの積率相関係数 | デフォルト |
| method = “spearman” | スピアマンの順位相関係数 | ノンパラメトリック |
| method = “kendall” | ケンドールの順位相関係数 | ノンパラメトリック |
psych::pairs.panels(iris, method = "pearson")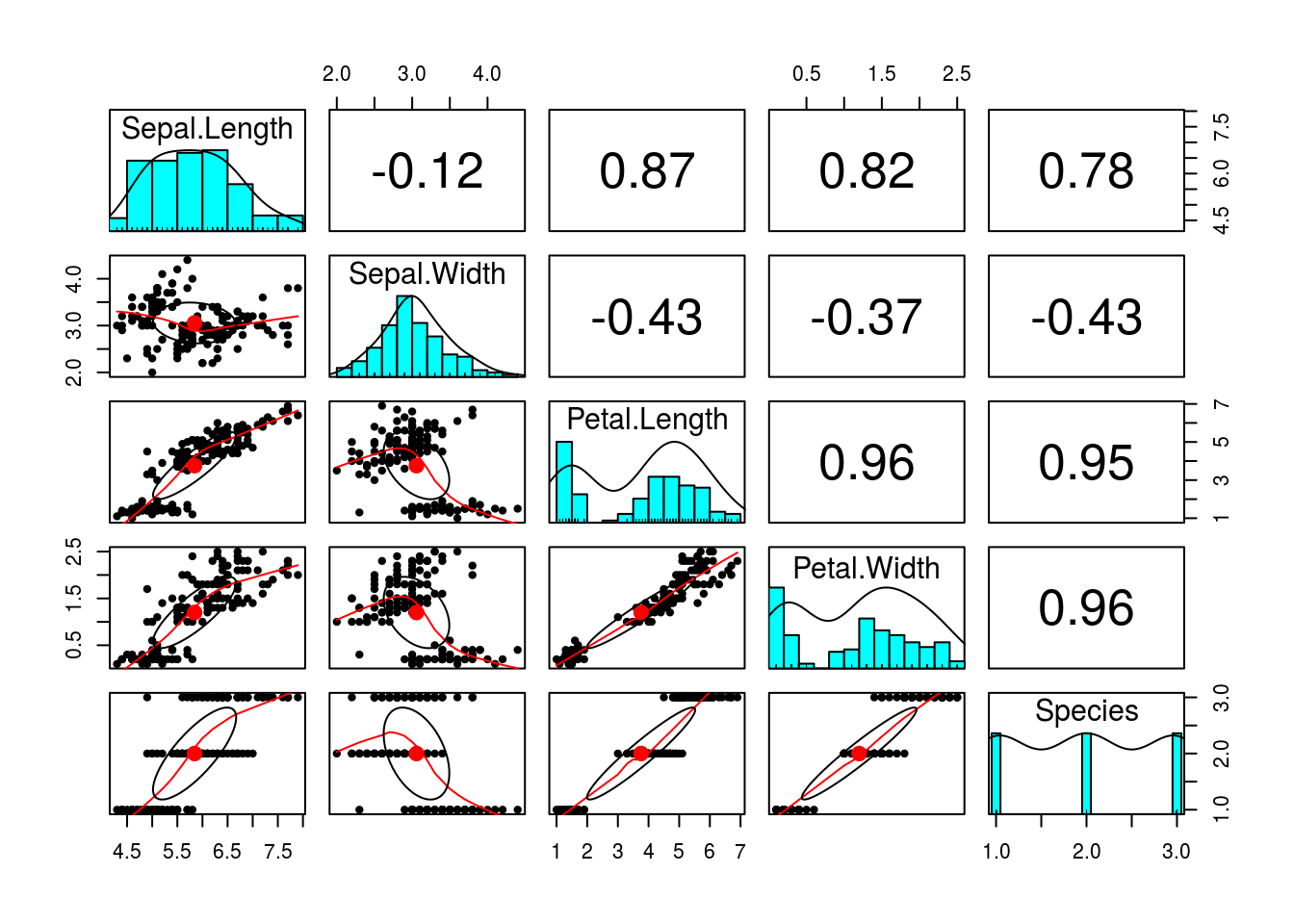
その他のオプションについてはヘルプを参照してください。
Package GGally
ggplot2風の散布図行列を描けるのがGGally::ggscatmatです。GGally::ggpairs関数と異なりカテゴリカルデータ(因子型データ)は描画の適用外となります。ただし、mtcarsデータセットのようにカテゴリカルデータでも因子型データになっていない場合には描画対象となりますので注意してください。
iris %>%
GGally::ggscatmat()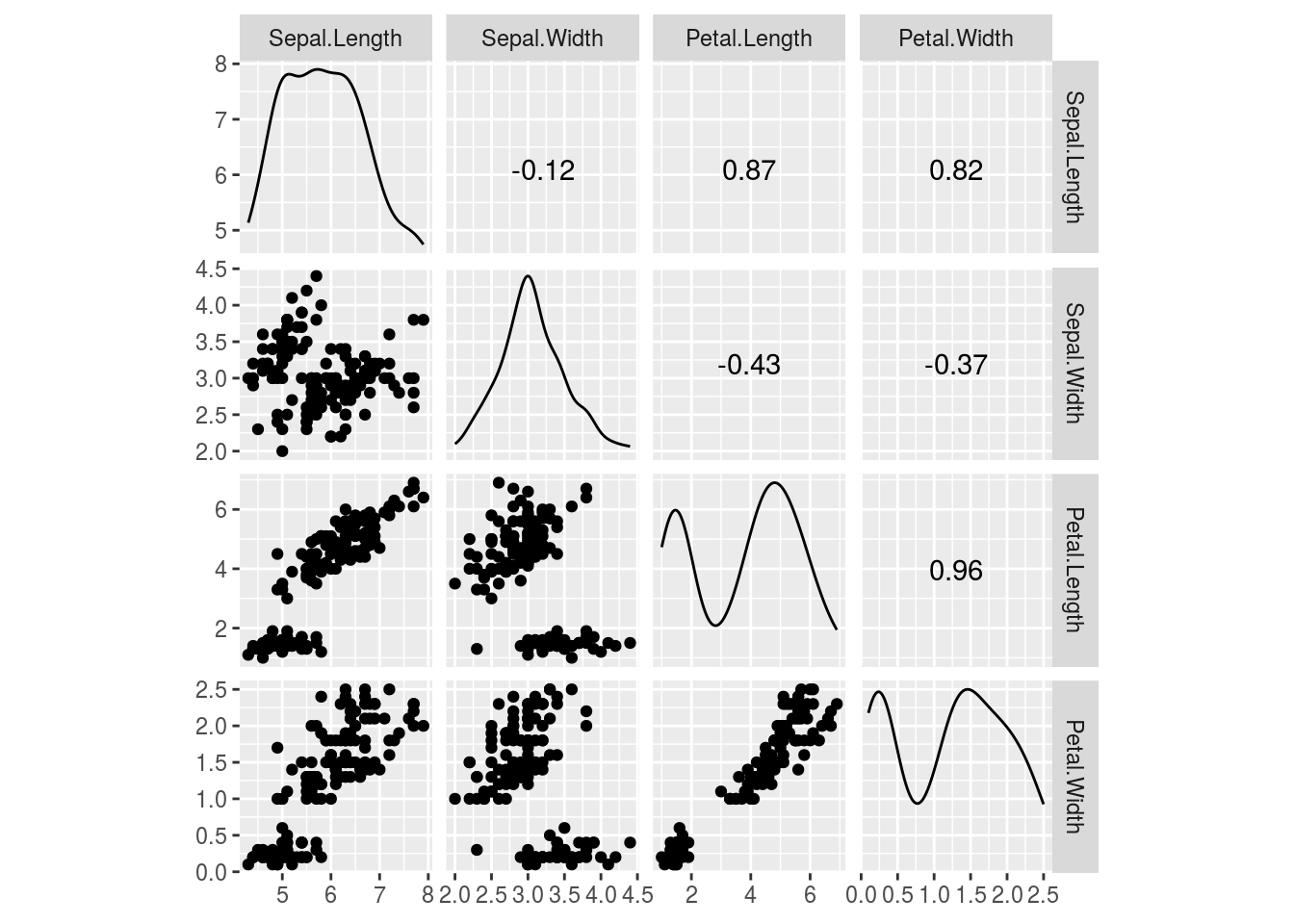
psych::pairs.panels関数と同様に相関係数の計算方法を指定できます。デフォルトではpearsonの積率相関係数ですがcorMethodオプションの指定によりkendallのτやspearmanのρの計算も可能です。
| 指定方法 | 計算される相関係数 | 備考 |
|---|---|---|
| corMethod = “pearson” | ピアソンの積率相関係数 | デフォルト |
| corMethod = “spearman” | スピアマンの順位相関係数 | ノンパラメトリック |
| corMethod = “kendall” | ケンドールの順位相関係数 | ノンパラメトリック |
GGally::ggscatmat関数は残念ながらggplot2風な散布図行列を描く関数でggplot2パッケージの各関数と連携させることはできません。ですので層別描画したい場合はggplot2::aes関数ではなくcolorオプションで指定してください。ggplot2パッケージと連携したい場合には後述のGGally::ggpairs関数を用いてください。
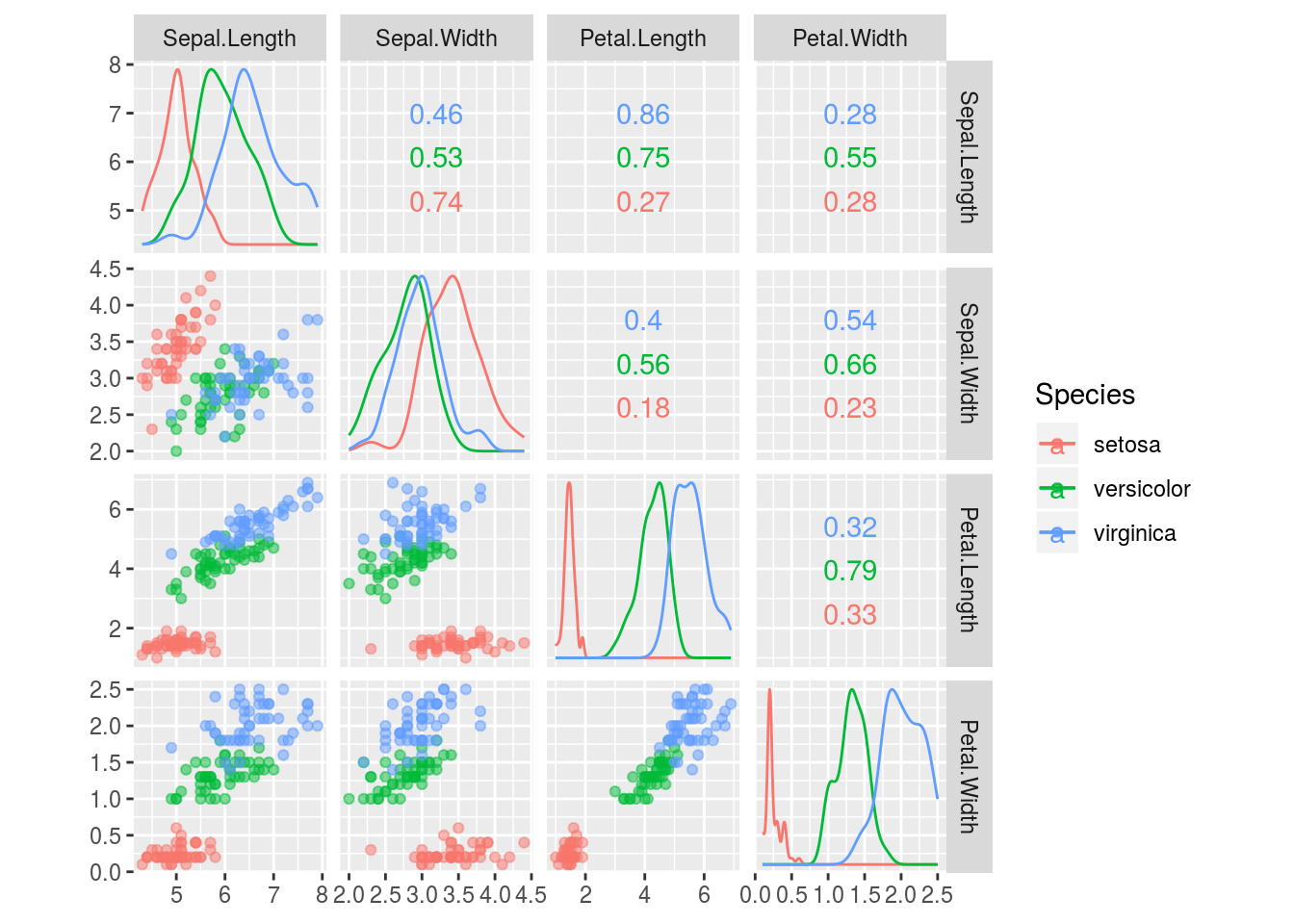
iris %>%
GGally::ggscatmat(color = 'Species', alpha = 0.5)