データクレンジングとは IT用語辞典 によると「データベースに保存されているデータの中から、重複や誤記、表記の揺れなどを探し出し、削除や修正、正規化などを行い、データの品質を高めること。」と説明されています。よく見かけるクレンジング対象になるデータ例としては
- 欠損値
- 全角文字と半角文字の混在
- 空白の有無
- 区切り文字の有無や揺れ
などがあります。特にデータ入力がフリフォーマットの場合はクレンジングを行わないと使い物にならないデータが多くなる傾向があるようにみえます。
Packages and Datasets
本ページではR version 3.4.4 (2018-03-15)の標準パッケージ以外に以下の追加パッケージを用いています。
| Package | Version | Description |
|---|---|---|
| tidyverse | 1.2.1 | Easily Install and Load the ‘Tidyverse’ |
| imputeMissings | 0.0.3 | Impute Missing Values in a Predictive Context |
| mice | 3.3.0 | Multivariate Imputation by Chained Equations |
| VIM | 4.7.0 | Visualization and Imputation of Missing Values |
また、本ページでは以下のデータセットを用いています。
| Dataset | Package | Version | Description |
|---|---|---|---|
| airquality | datasets | 3.4.4 | New York Air Quality Measurements |
欠損値処理
データには必ずと言っていいほどレコードの一部のデータが取得できていないものが含まれます。取得できていないデータを欠損値と呼びます。Rで欠損値を含んだデータを読み込んだ場合、デフォルト処理では欠損値はNAという特殊なデータとして処理されます。
欠損値の扱いはデータや分析目的などにより変わりますが、扱い方は大きく以下のように三つに分類されます。
- 欠損値をそのまま扱う
- 欠損値を削除する
- 欠損値を補完する
欠損値を削除する
欠損値を含むレコードは不完全なものとして分析対象外として扱う方法です。欠損値を削除する代表的な方法には下表のような方法があります。
| 方法 | 詳細 |
|---|---|
| リストワイズ法 | 欠損値を持つレコード全てを削除します |
| ペアワイズ法 | 統計量の算出に関わる二変数のいずれかに欠損値があるレコードを削除します |
Base Rにはna.omit関数が用意されていますが、na.omit関数はNAを含む全てのレコードを削除します。特定の変数にNAが含まれている場合にのみNAを削除したい場合にはtidyr::drop_na関数を用います。
リストワイズ法
リストワイズ法によりtidyr::drop_na関数はNAを含む全てのレコードを削除する場合は以下のように行います。
airquality %>%
tidyr::drop_na() %>%
head()## # A tibble: 6 x 6
## Ozone Solar.R Wind Temp Month Day
## * <int> <int> <dbl> <int> <int> <int>
## 1 41 190 7.4 67 5 1
## 2 36 118 8 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 23 299 8.6 65 5 7
## 6 19 99 13.8 59 5 8
ペアワイズ法
例えばSolar.R変数とWind変数を用いて統計量を計算するために両変数ともNAであるレコードのみを削除するペアワイズ法の場合には
- 統計量計算時のみ当該レコードを削除する
- データセットからレコードを削除する
の二つの方法が考えられますが基本的には全社の統計量計算時のみ欠損値のあるレコードを削除するアプローチを用いるようです(確認中)。例えば相関係数を計算するにはuseオプションで"pairwise.complete.obs"を指定します。
cor(airquality$Solar.R, airquality$Wind, use = "pairwise.complete.obs")## [1] -0.05679167
同様に分散(var)や共分散(cov)でも同様のオプション指定が可能です。
データセットから任意の二変数が共にNAの場合のレコードを削除するには以下のような方法があります。
airquality %>%
dplyr::mutate(flag = Solar.R | Ozone) %>%
tidyr::drop_na(flag) %>%
dplyr::select(-flag) %>%
head()## # A tibble: 6 x 6
## Ozone Solar.R Wind Temp Month Day
## * <int> <int> <dbl> <int> <int> <int>
## 1 41 190 7.4 67 5 1
## 2 36 118 8 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 28 NA 14.9 66 5 6
## 6 23 299 8.6 65 5 7
欠損値を補完する
データ収集対象の性格などにより欠損値の発生が避けられない場合や取得したデータをなるべく活かしたい場合に欠損値を推定して補完する方法があります。
| 方法 | 詳細 |
|---|---|
| 平均値代入法 | 平均値を用いて欠損値を補完します |
| 回帰代入法 | 欠損値を削除したデータから回帰分析を行いその推定値を用いて欠損値を補完します |
| 確率的回帰代入法 | 回帰代入法で得られた推定値にランダム誤差を加えた値で欠損値を補完します |
| 完全情報最尤推定法 | 欠損パターンに応じた尤度関数で最尤推定を行い推定値を求めます |
| 多重代入法 | 欠損値を代入した複数のデータセットを作成してそこから欠損値を推測します |
| その他の方法 | その他機械学習を用いた補完方法など |
上記以外にも変数の性格から欠損値に特定値(例えばゼロ)を割り当てる方法もよく使われる方法です。
欠損値の補完や削除方法をairqularityデータセットを用いて説明します。airqualityデータセットは6つの変数それぞれに「37, 7, 0, 0, 0, 0」個のNAを含むデータセットです。このデータセットを用いてNAの代表的な処理例を示します。
airquality %>%
head()## # A tibble: 6 x 6
## Ozone Solar.R Wind Temp Month Day
## * <int> <int> <dbl> <int> <int> <int>
## 1 41 190 7.4 67 5 1
## 2 36 118 8 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 NA NA 14.3 56 5 5
## 6 28 NA 14.9 66 5 6
単一代入法
平均値や回帰値を用いて欠損値を補完する方法を後述の多重代入法と対比させて単一代入法と呼びます。単一代入法のように欠損値を特定の値に変換する場合は、まず変数の値がNAであるか否かを判断する必要があります。これにはis.na関数を用います。例えばOzone変数のNAをOzone変数の平均値に変換する場合はifelse関数と組み合わせて処理を行います。
ozone <- airquality %>%
dplyr::summarise(ozone_mean = round(mean(Ozone, na.rm = TRUE), 0))
airquality %>%
dplyr::mutate(ozone = ifelse(is.na(Ozone), ozone$ozone_mean, Ozone)) %>%
dplyr::select(Ozone, ozone, Solar.R, Wind, Temp, Month, Day) %>%
head()## # A tibble: 6 x 7
## Ozone ozone Solar.R Wind Temp Month Day
## * <int> <dbl> <int> <dbl> <int> <int> <int>
## 1 41 41 190 7.4 67 5 1
## 2 36 36 118 8 72 5 2
## 3 12 12 149 12.6 74 5 3
## 4 18 18 313 11.5 62 5 4
## 5 NA 42 NA 14.3 56 5 5
## 6 28 28 NA 14.9 66 5 6
平均値代入法の結果を可視化すると下図のようになります。赤線の部分が欠損値を平均値で補完したものです。このような時系列データには不向きな手法に見えます。
airquality %>%
dplyr::mutate(Ozone = ifelse(is.na(Ozone), ozone$ozone_mean, Ozone)) %>%
dplyr::bind_cols(airquality) %>%
dplyr::select(Ozone, Ozone1) %>%
tibble::rowid_to_column("days") %>%
ggplot2::ggplot(ggplot2::aes(x = days)) +
ggplot2::geom_line(ggplot2::aes(y = Ozone), colour = "red") +
ggplot2::geom_line(ggplot2::aes(y = Ozone1), colour = "blue")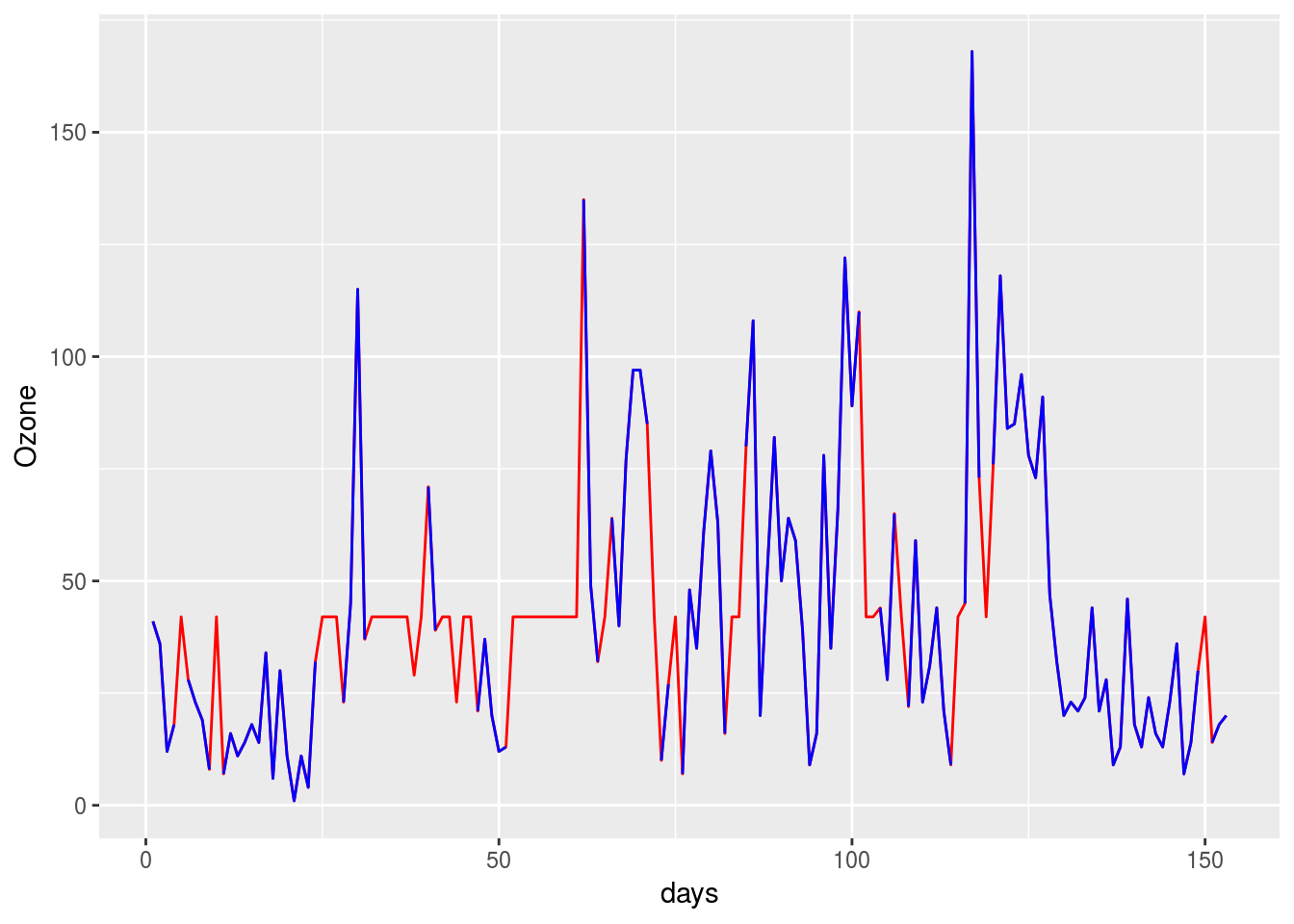
多重代入法
多重代入法は確率的代入の考えに基づき欠損値を疑似的に補完したデータ(疑似完全データという)を複数作成し、全ての擬似完全データを分析、それらの分析結果を統合して結論(推定値)を出すという代入、解析、統合の三段階で値を導き出す方法です。一口に多重代入法といっても様々なアルゴリズムが提案されていますが、ここで扱う多重代入法はMICE(連鎖方程式による多変量補定)によるものです。
と書くと何やら難しそうですが、前出のmiceパッケージを利用することで計算自体は簡単に行えます。例えば、airqualityデータセットではOnone変数とSolar.R変数にある欠損値を多重代入法で補完するには以下を実行するだけで済みます。
(aq_mice <- airquality %>%
mice::mice(printFlag = FALSE, seed = 0) %>%
mice::complete()) %>%
head()## # A tibble: 6 x 6
## Ozone Solar.R Wind Temp Month Day
## * <int> <int> <dbl> <int> <int> <int>
## 1 41 190 7.4 67 5 1
## 2 36 118 8 72 5 2
## 3 12 149 12.6 74 5 3
## 4 18 313 11.5 62 5 4
## 5 37 101 14.3 56 5 5
## 6 28 220 14.9 66 5 6
補完結果がどのようになっているか確認してみます。下図において赤線の部分が欠損値を補完したものです。平均値代入法(単一代入法)にくらべるとかなり“らしい”感じになっていると思います。
aq_mice %>%
dplyr::bind_cols(airquality) %>%
dplyr::select(Ozone, Ozone1) %>%
tibble::rowid_to_column("days") %>%
ggplot2::ggplot(ggplot2::aes(x = days)) +
ggplot2::geom_line(ggplot2::aes(y = Ozone), colour = "red") +
ggplot2::geom_line(ggplot2::aes(y = Ozone1), colour = "blue")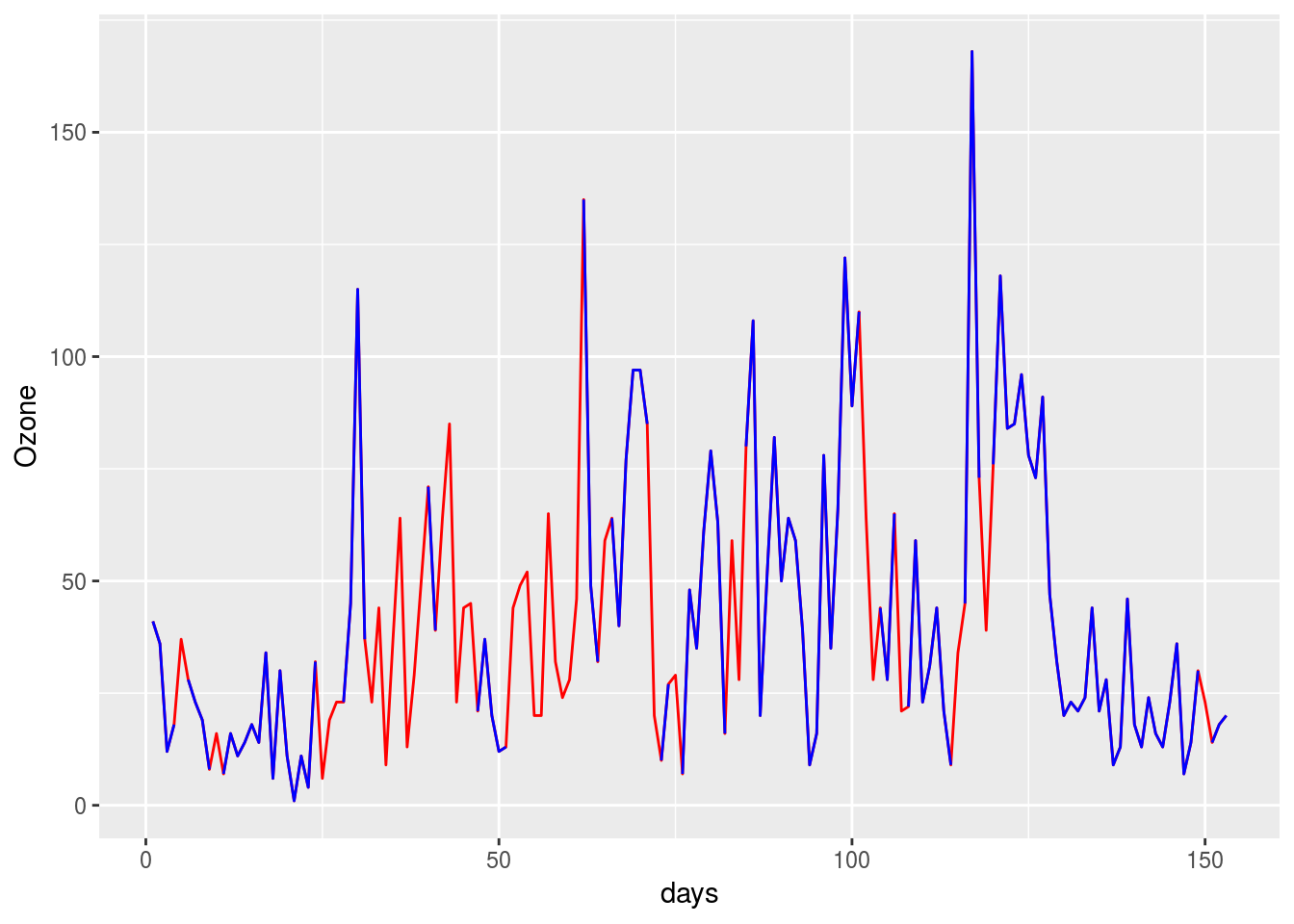
注意事項
多重代入法は乱数を用いますので、本ページではmice::mice関数にseedオプションを指定して発生する乱数を固定することで再現性を確保しています。また、疑似完全データの数はデフォルトのm = 5を使用しています。疑似完全データの数は歴史的にはデフォルト値であるm = 5程度と言われてきたようですが、最近では計算機の処理速度も上がってきているためm = 20くらいが目安と言われているようです。 参考までにmice::mice関数が計算した疑似完全データセットの密度分布(赤線)を下図に示します。疑似完全データ数が多い方が青線の元データ(欠損値を含むデータの密度分布)から大きく外れた値を計算していないように見えます。
airquality %>%
mice::mice(printFlag = FALSE, seed = 0) %>%
densityplot()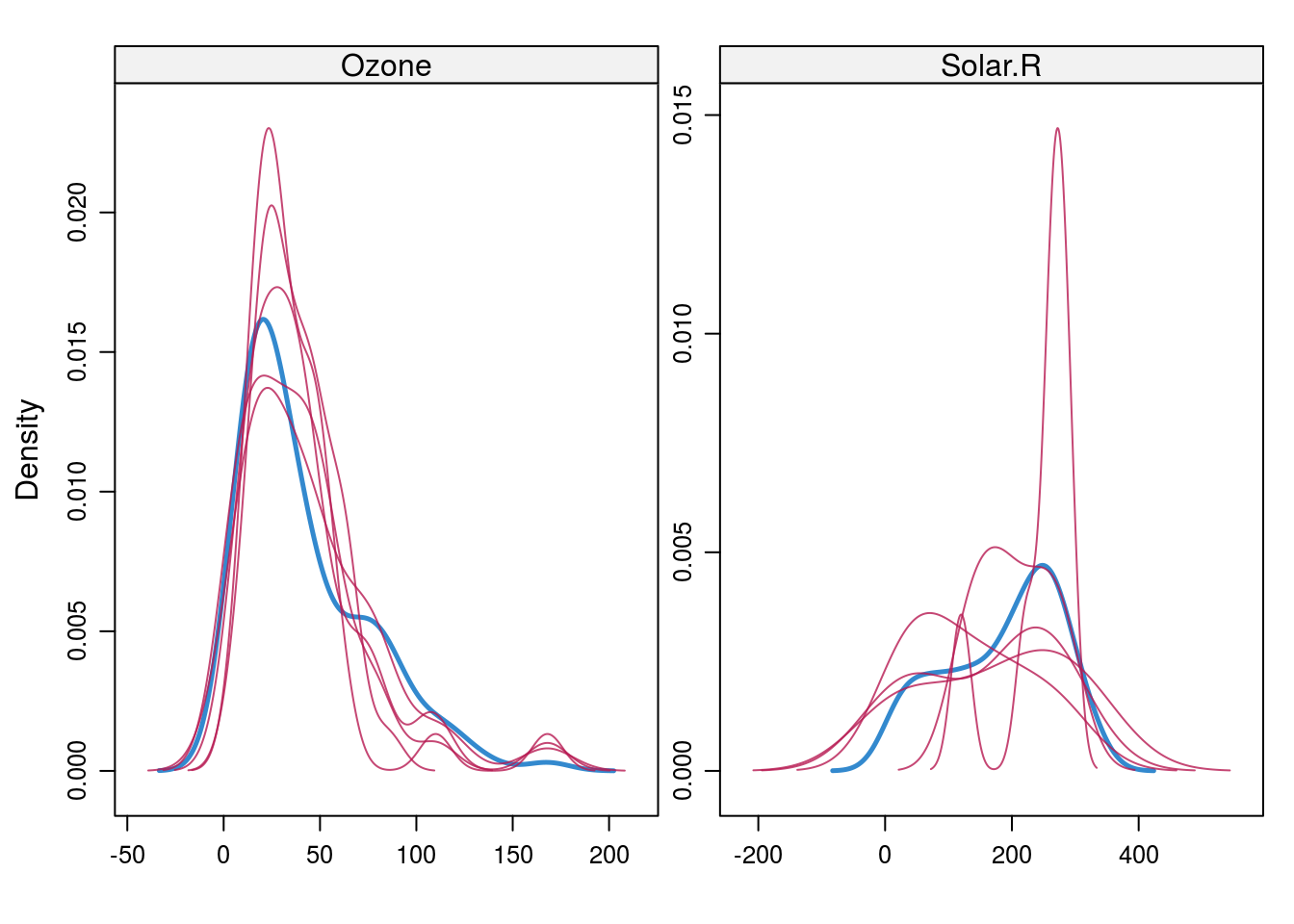
airquality %>%
mice::mice(m = 20, printFlag = FALSE, seed = 0) %>%
densityplot()
機械学習による補完
Rでは機械学習(ランダムフォレスト)による欠損値の補完をimputeMissingsパッケージを用いて行うことができます。imputeMissings::compute関数を用いて学習データを作成しimputeMissings::impute関数で補完する値を求めますが、学習データの用意ができない場合でも以下のように対象データを元に演算を行ってくれます。
airquality %>%
imputeMissings::impute(method = "randomForest") %>%
dplyr::bind_cols(airquality) %>%
dplyr::select(Ozone, Ozone1) %>%
tibble::rowid_to_column("days") %>%
ggplot2::ggplot(ggplot2::aes(x = days)) +
ggplot2::geom_line(ggplot2::aes(y = Ozone), colour = "red") +
ggplot2::geom_line(ggplot2::aes(y = Ozone1), colour = "blue")