R によるデータハンドリングの有用性を実感してもらうためにアンスコム(anscombe)のデータ例を用いて説明します。なお、この説明の元資料は参考資料として最下段に示したあります。
Packages and Datasets
本ページではR version 3.4.4 (2018-03-15)の標準パッケージ以外に以下の追加パッケージを用いています。
| Package | Version | Description |
|---|---|---|
| tidyverse | 1.2.1 | Easily Install and Load the ‘Tidyverse’ |
また、本ページでは以下のデータセットを用いています。
| Dataset | Package | Version | Description |
|---|---|---|---|
| anscombe | datasets | 3.4.4 | Anscombe’s Quartet of ‘Identical’ Simple Linear Regressions |
アンスコムのデータ例
アンスコムのデータ例は R の標準パッケージにanscombeデータセットとして格納されており、具体的には下表のような形式になっています。
anscombe## # A tibble: 11 x 8
## x1 x2 x3 x4 y1 y2 y3 y4
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 10 10 10 8 8.04 9.14 7.46 6.58
## 2 8 8 8 8 6.95 8.14 6.77 5.76
## 3 13 13 13 8 7.58 8.74 12.7 7.71
## 4 9 9 9 8 8.81 8.77 7.11 8.84
## 5 11 11 11 8 8.33 9.26 7.81 8.47
## 6 14 14 14 8 9.96 8.1 8.84 7.04
## 7 6 6 6 8 7.24 6.13 6.08 5.25
## 8 4 4 4 19 4.26 3.1 5.39 12.5
## 9 12 12 12 8 10.8 9.13 8.15 5.56
## 10 7 7 7 8 4.82 7.26 6.42 7.91
## 11 5 5 5 8 5.68 4.74 5.73 6.89
データは(x1, y1)、(x2, y2) …… で組になっており4組のデータ全ての平均値、分散、相関係数、共分散が同じという性質を持っています。
## # A tibble: 4 x 7
## グループ `平均値(x)` `平均値(y)` `分散(x)` `分散(y)` 相関係数 共分散
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 9 7.5 3.32 2.03 0.82 5.5
## 2 2 9 7.5 3.32 2.03 0.82 5.5
## 3 3 9 7.5 3.32 2.03 0.82 5.5
## 4 4 9 7.5 3.32 2.03 0.82 5.5
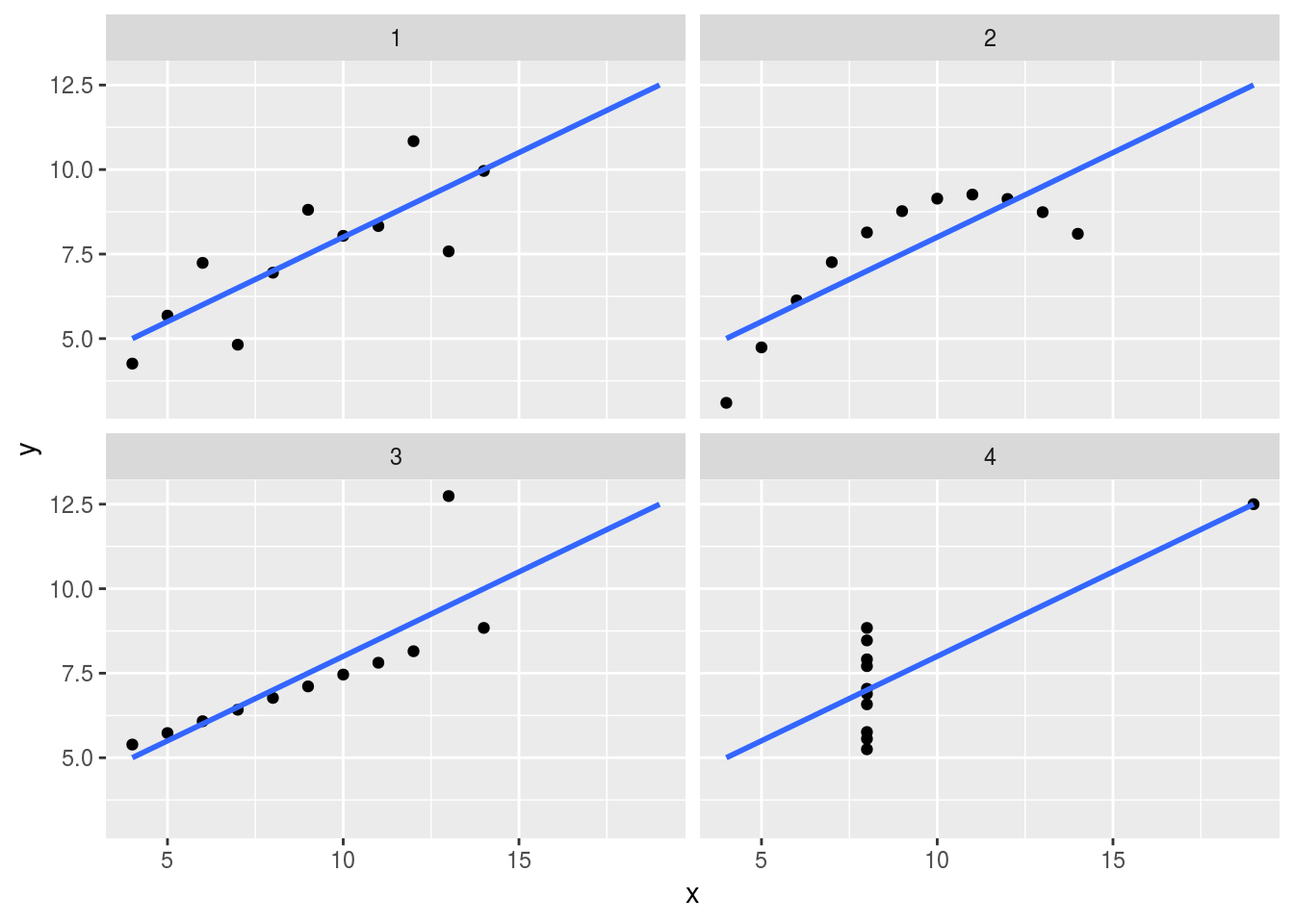
ところが、散布図を描いてみるとデータの分布は4組全てが異なっており、一概に要約統計量だけで判断してはならないという非常に教訓に満ちたデータです。
データハンドリング
では、このアンスコムのデータ例を用いて実際に要約統計量とグラフを描いてみましょう。
anscombe## # A tibble: 11 x 8
## x1 x2 x3 x4 y1 y2 y3 y4
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 10 10 10 8 8.04 9.14 7.46 6.58
## 2 8 8 8 8 6.95 8.14 6.77 5.76
## 3 13 13 13 8 7.58 8.74 12.7 7.71
## 4 9 9 9 8 8.81 8.77 7.11 8.84
## 5 11 11 11 8 8.33 9.26 7.81 8.47
## 6 14 14 14 8 9.96 8.1 8.84 7.04
## 7 6 6 6 8 7.24 6.13 6.08 5.25
## 8 4 4 4 19 4.26 3.1 5.39 12.5
## 9 12 12 12 8 10.8 9.13 8.15 5.56
## 10 7 7 7 8 4.82 7.26 6.42 7.91
## 11 5 5 5 8 5.68 4.74 5.73 6.89
Tidy Data形式に変換する
アンスコムのデータ例は見てわかるように雑然(Messy)データ形式ですので、まず、これを整然(Tidy)データ形式に変換します。
列を識別できるようにする
anscombe %>%
tibble::rownames_to_column("id")## # A tibble: 11 x 9
## id x1 x2 x3 x4 y1 y2 y3 y4
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 10 10 10 8 8.04 9.14 7.46 6.58
## 2 2 8 8 8 8 6.95 8.14 6.77 5.76
## 3 3 13 13 13 8 7.58 8.74 12.7 7.71
## 4 4 9 9 9 8 8.81 8.77 7.11 8.84
## 5 5 11 11 11 8 8.33 9.26 7.81 8.47
## 6 6 14 14 14 8 9.96 8.1 8.84 7.04
## 7 7 6 6 6 8 7.24 6.13 6.08 5.25
## 8 8 4 4 4 19 4.26 3.1 5.39 12.5
## 9 9 12 12 12 8 10.8 9.13 8.15 5.56
## 10 10 7 7 7 8 4.82 7.26 6.42 7.91
## 11 11 5 5 5 8 5.68 4.74 5.73 6.89
列をまとめる
次に列をまとめて座標軸をあらわすaxisと値をあらわすvalueに集約します。
anscombe %>%
tibble::rownames_to_column("id") %>%
tidyr::gather(key = axis, value, -id)## # A tibble: 88 x 3
## id axis value
## <chr> <chr> <dbl>
## 1 1 x1 10
## 2 2 x1 8
## 3 3 x1 13
## 4 4 x1 9
## 5 5 x1 11
## 6 6 x1 14
## 7 7 x1 6
## 8 8 x1 4
## 9 9 x1 12
## 10 10 x1 7
## # ... with 78 more rows
この時点で整然(Tidy)データのように見えますが、axisには二つの意味(座標軸とグループ)を持ったデータが格納されていますので、これらは分割する必要があります。
軸名を分割する
x1, x2, …, y3, y4という軸名を軸を表すaxisとグループをあらわすgroupに分割します。
anscombe %>%
tibble::rownames_to_column("id") %>%
tidyr::gather(key = axis, value, -id) %>%
tidyr::separate(axis, c("axis", "group"), 1)## # A tibble: 88 x 4
## id axis group value
## <chr> <chr> <chr> <dbl>
## 1 1 x 1 10
## 2 2 x 1 8
## 3 3 x 1 13
## 4 4 x 1 9
## 5 5 x 1 11
## 6 6 x 1 14
## 7 7 x 1 6
## 8 8 x 1 4
## 9 9 x 1 12
## 10 10 x 1 7
## # ... with 78 more rows
この時点でもaxisには二つの意味(x軸とy軸)を持ったデータが格納されていますので、これらも分割する必要があります(x軸、y軸は因子の水準ではなく、それぞれ異なった意味を持つ変数と見なせます。一方、グループは4つの水準を持つ因子と見なすこと出来ますのでこちらを分割する必要はありません)。
座標軸を整理する
x軸とy軸が同じaxis列に集約されていますのでxとyという二つの列に分割します。
anscombe %>%
tibble::rownames_to_column("id") %>%
tidyr::gather(key = axis, value, -id) %>%
tidyr::separate(axis, c("axis", "group"), 1) %>%
tidyr::spread(axis, value)## # A tibble: 44 x 4
## id group x y
## <chr> <chr> <dbl> <dbl>
## 1 1 1 10 8.04
## 2 1 2 10 9.14
## 3 1 3 10 7.46
## 4 1 4 8 6.58
## 5 10 1 7 4.82
## 6 10 2 7 7.26
## 7 10 3 7 6.42
## 8 10 4 8 7.91
## 9 11 1 5 5.68
## 10 11 2 5 4.74
## # ... with 34 more rows
不要列を削除する
最初に付加した列を識別するためのid列を削除して整然(Tidy)データの完成です。
anscombe %>%
tibble::rownames_to_column("id") %>%
tidyr::gather(key, value, -id) %>%
tidyr::separate(key, c("axis", "group"), 1) %>%
tidyr::spread(axis, value) %>%
dplyr::select(-id)## # A tibble: 44 x 3
## group x y
## <chr> <dbl> <dbl>
## 1 1 10 8.04
## 2 2 10 9.14
## 3 3 10 7.46
## 4 4 8 6.58
## 5 1 7 4.82
## 6 2 7 7.26
## 7 3 7 6.42
## 8 4 8 7.91
## 9 1 5 5.68
## 10 2 5 4.74
## # ... with 34 more rows